
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER Exam Questions & Answers
Exam Code: DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Exam Name: Databricks Certified Professional Data Engineer Exam
Updated:
Q&As: 120
At Passcerty.com, we pride ourselves on the comprehensive nature of our DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER exam dumps, designed meticulously to encompass all key topics and nuances you might encounter during the real examination. Regular updates are a cornerstone of our service, ensuring that our dedicated users always have their hands on the most recent and relevant Q&A dumps. Behind every meticulously curated question and answer lies the hard work of our seasoned team of experts, who bring years of experience and knowledge into crafting these premium materials. And while we are invested in offering top-notch content, we also believe in empowering our community. As a token of our commitment to your success, we're delighted to offer a substantial portion of our resources for free practice. We invite you to make the most of the following content, and wish you every success in your endeavors.
Download Free Databricks DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER Demo
Experience Passcerty.com exam material in PDF version.
Simply submit your e-mail address below to get started with our PDF real exam demo of your Databricks DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER exam.
![]() Instant download
Instant download
![]() Latest update demo according to real exam
Latest update demo according to real exam
* Our demo shows only a few questions from your selected exam for evaluating purposes
Free Databricks DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER Dumps
Practice These Free Questions and Answers to Pass the Databricks Certification Exam
An hourly batch job is configured to ingest data files from a cloud object storage container where each batch represent all records produced by the source system in a given hour. The batch job to process these records into the Lakehouse is sufficiently delayed to ensure no late-arriving data is missed. Theuser_idfield represents a unique key for the data, which has the following schema:
user_id BIGINT, username STRING, user_utc STRING, user_region STRING, last_login BIGINT, auto_pay BOOLEAN, last_updated BIGINT
New records are all ingested into a table namedaccount_historywhich maintains a full record of all data in the same schema as the source. The next table in the system is namedaccount_currentand is implemented as a Type 1 table representing the most recent value for each uniqueuser_id.
Assuming there are millions of user accounts and tens of thousands of records processed hourly, which implementation can be used to efficiently update the describedaccount_currenttable as part of each hourly batch job?
A. Use Auto Loader to subscribe to new files in the account history directory; configure a Structured Streaminq trigger once job to batch update newly detected files into the account current table.
B. Overwrite the account current table with each batch using the results of a query against the account history table grouping by user id and filtering for the max value of last updated.
C. Filter records in account history using the last updated field and the most recent hour processed, as well as the max last iogin by user id write a merge statement to update or insert the most recent value for each user id.
D. Use Delta Lake version history to get the difference between the latest version of account history and one version prior, then write these records to account current.
E. Filter records in account history using the last updated field and the most recent hour processed, making sure to deduplicate on username; write a merge statement to update or insert the most recent value for each username.
Each configuration below is identical to the extent that each cluster has 400 GB total of RAM, 160 total cores and only one Executor per VM.
Given a job with at least one wide transformation, which of the following cluster configurations will result in maximum performance?
A. Total VMs; 1 400 GB per Executor 160 Cores / Executor
B. Total VMs: 8 50 GB per Executor 20 Cores / Executor
C. Total VMs: 4 100 GB per Executor 40 Cores/Executor
D. Total VMs:2 200 GB per Executor 80 Cores / Executor
An upstream system has been configured to pass the date for a given batch of data to the Databricks Jobs API as a parameter. The notebook to be scheduled will use this parameter to load data with the following code:
df = spark.read.format("parquet").load(f"/mnt/source/(date)")
Which code block should be used to create the date Python variable used in the above code block?
A. date = spark.conf.get("date")
B. input_dict = input() date= input_dict["date"]
C. import sys date = sys.argv[1]
D. date = dbutils.notebooks.getParam("date")
E. dbutils.widgets.text("date", "null") date = dbutils.widgets.get("date")
A table is registered with the following code:
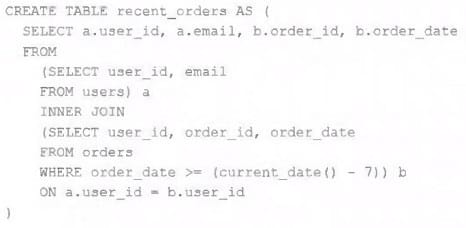
Bothusersandordersare Delta Lake tables. Which statement describes the results of queryingrecent_orders?
A. All logic will execute at query time and return the result of joining the valid versions of the source tables at the time the query finishes.
B. All logic will execute when the table is definedand store the result of joiningtables to the DBFS; this stored data will be returned when the table is queried.
C. Results will be computed and cached when the table is defined; these cached results will incrementally update as new records are inserted into source tables.
D. All logic will execute at query time and return the result of joining the valid versions of the source tables at the time the query began.
E. The versions of each source table will be stored in the table transaction log; query results will be saved to DBFS with each query.
Which of the following is true of Delta Lake and the Lakehouse?
A. Because Parquet compresses data row by row. strings will only be compressed when a character is repeated multiple times.
B. Delta Lake automatically collects statistics on the first 32 columns of each table which are leveraged in data skipping based on query filters.
C. Views in the Lakehouse maintain a valid cache of the most recent versions of source tables at all times.
D. Primary and foreign key constraints can be leveraged to ensure duplicate values are never entered into a dimension table.
E. Z-order can only be applied to numeric values stored in Delta Lake tables
Viewing Page 1 of 3 pages. Download PDF or Software version with 120 questions

Home | Contact Us | About Us | FAQ | Guarantee & Policy | Privacy & Policy | Terms & Conditions | How to buy
Copyright © 2024 passcerty.com. All Rights Reserved